High School Math Worksheet Statistics
A high school math worksheet on statistics is designed to provide students with an in-depth understanding of statistical concepts and their real-world applications. By focusing on the various entities and subjects within statistical analysis, this worksheet aims to equip students with the necessary skills to interpret and analyze data accurately.
Table of Images 👆
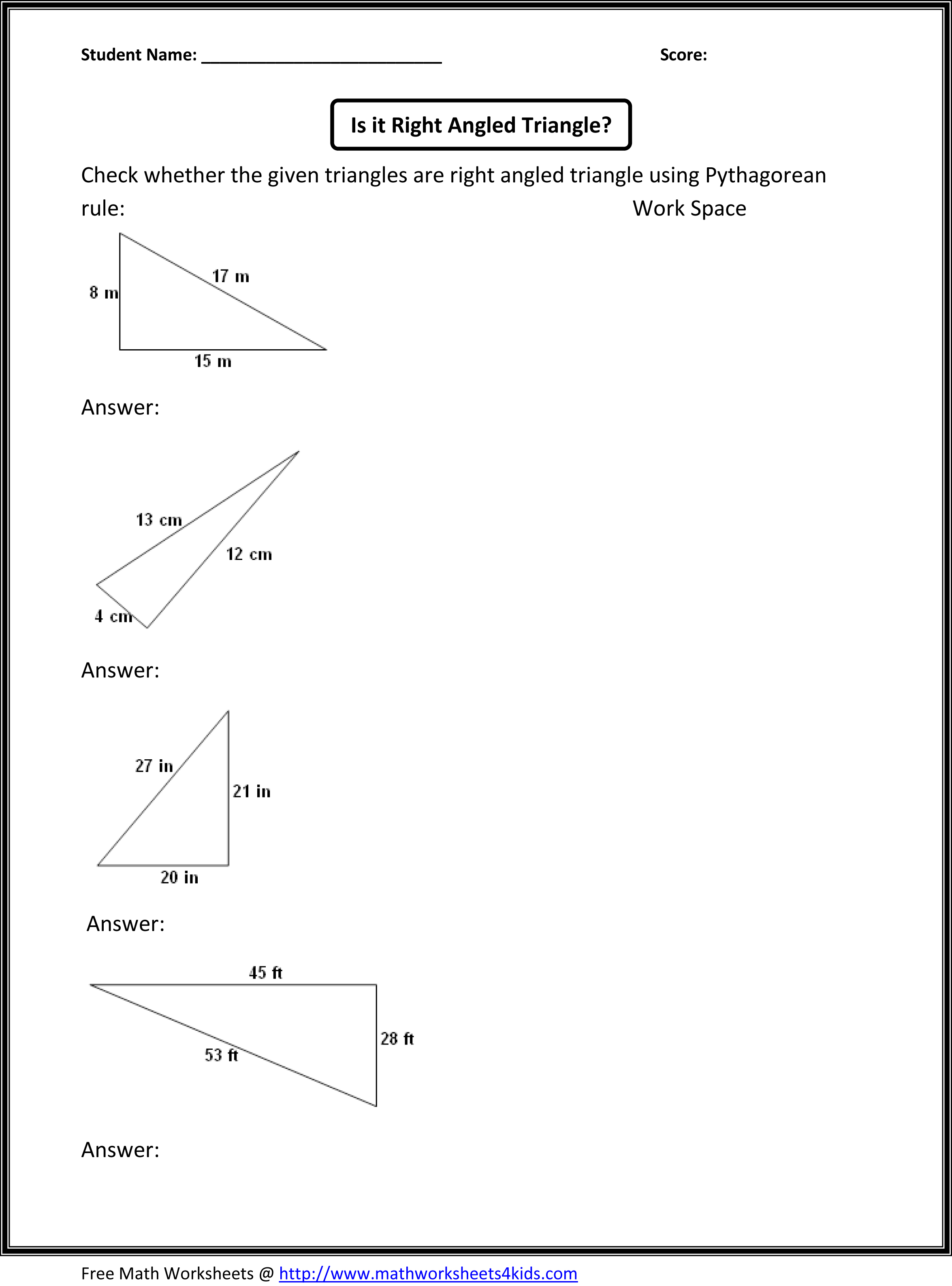
 8th Grade Math Worksheets Geometry
8th Grade Math Worksheets Geometry
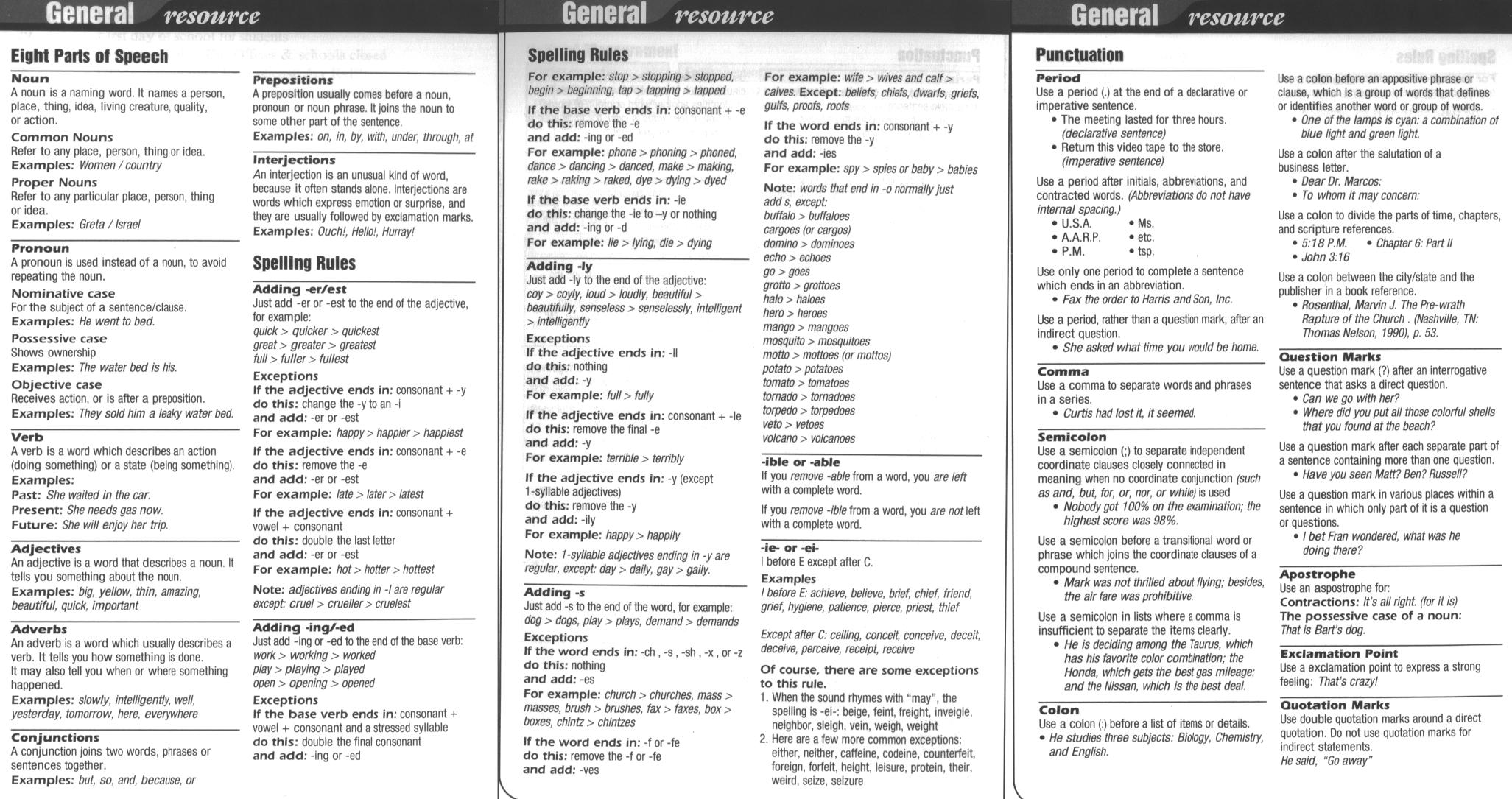
 Grammar Rules Chart Printable
Grammar Rules Chart Printable

 Everyday Math Worksheets Printable
Everyday Math Worksheets Printable
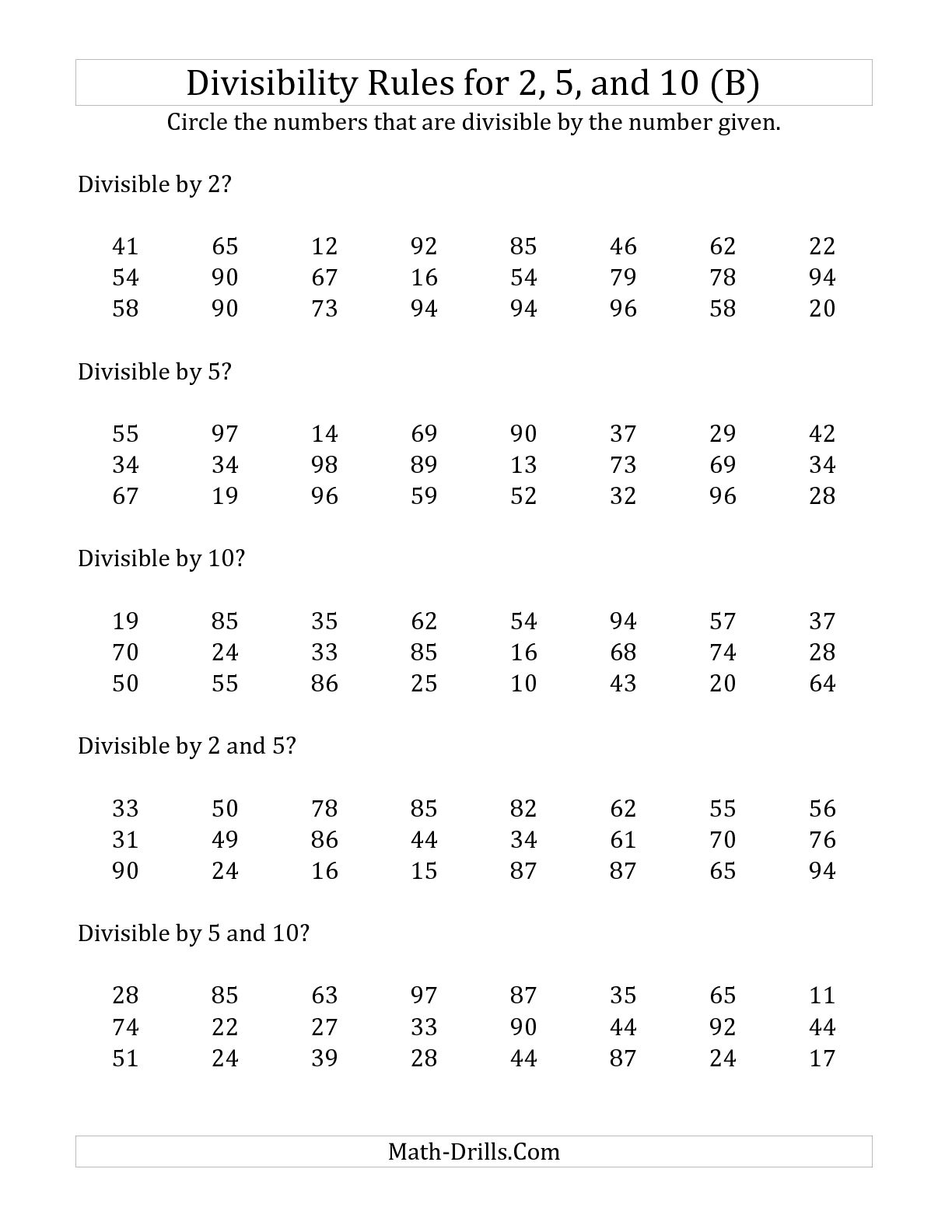
 3 by 2 Digit Division Worksheets
3 by 2 Digit Division Worksheets
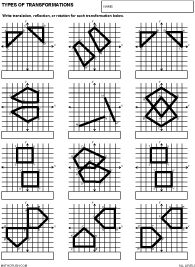
 Types of Math Transformation Worksheets
Types of Math Transformation Worksheets

 Simple and Compound Interest Worksheets
Simple and Compound Interest Worksheets

 Circle Graph Worksheets 8th Grade
Circle Graph Worksheets 8th Grade

 8th Grade Math Worksheets Algebra
8th Grade Math Worksheets Algebra
More Math Worksheets
Printable Math WorksheetsMath Worksheets Printable
Printable Math Worksheets Multiplication
Math Worksheets for 2nd Graders
Math Practice Worksheet Grade 6
Math Multiplication Worksheets
First Grade Subtraction Math Worksheets Printable
Math Worksheets Integers
Superhero Math Worksheets
Middle School Math Coloring Worksheets
What is the difference between descriptive and inferential statistics?
Descriptive statistics are used to summarize and describe data using measures such as mean, median, and standard deviation, while inferential statistics involve making inferences and predictions about a population based on a sample of data. Descriptive statistics aim to provide a clear and concise summary of the data, whereas inferential statistics are used to draw conclusions and make generalizations about a larger population beyond the sample data.
Define population and sample in the context of statistics.
In statistics, a population refers to the entire group of individuals, items, or events that are of interest to a researcher. A sample, on the other hand, is a subset of that population that is chosen for study and analysis. The purpose of sampling is to make inferences or draw conclusions about the population based on the data collected from the sample. The key is to ensure that the sample is selected in a way that is representative of the population to avoid biased results.
How do you calculate the mean, median, and mode?
To calculate the mean, add up all the values in a data set and divide by the total number of values. The median is found by arranging the values in numerical order and identifying the middle value if there is an odd number of values or calculating the average of the two middle values if the number of values is even. The mode is the value that appears most frequently in the data set. If multiple values have the same highest frequency, the data set is considered multimodal.
Explain the concept of standard deviation.
Standard deviation is a measure of the dispersion or variability of a set of values from the mean. It quantifies how much the values in a dataset differ from the average value. A small standard deviation indicates that the values are close to the mean, while a large standard deviation indicates that the values are spread out over a wider range. In statistics, standard deviation is often used to assess the consistency or stability of data points and is a key tool for evaluating the reliability of statistical results and making comparisons between different data sets.
What is a frequency distribution and how is it constructed?
A frequency distribution is a summary table that displays the number of occurrences of different values or categories in a dataset. It shows how data are distributed across different intervals or groups. To construct a frequency distribution, you first need to identify the range of values in the dataset and decide on the intervals or categories to group the data into. Then, count the number of data points that fall within each interval or category to create the frequency counts. Finally, you can display this information in a table or graph to visualize the distribution of the data.
What is the difference between a bar graph and a histogram?
The main difference between a bar graph and a histogram is that a bar graph represents categorical data with distinct categories on the x-axis and corresponding quantities on the y-axis, while a histogram represents numerical data with continuous intervals on the x-axis and frequencies or relative frequencies on the y-axis, showing the distribution of the data. Essentially, a bar graph displays counts of separate categories, while a histogram displays the distribution of continuous data.
What are outliers and how do they affect statistical analysis?
Outliers are data points that significantly differ from the rest of the dataset. They can skew statistical analysis by affecting measures of central tendency and dispersion, leading to inaccurate interpretations of the data. Outliers can also impact the results of statistical tests and models, potentially influencing the conclusions drawn from the analysis. It is important to identify and handle outliers appropriately to ensure the validity and reliability of statistical findings.
Define correlation and explain how it is measured.
Correlation is a statistical measure describing the extent to which two variables change together. It indicates the strength and direction of a linear relationship between variables. Correlation is typically measured using Pearson's correlation coefficient, which ranges from -1 to 1. A correlation coefficient of 1 signifies a perfect positive relationship, -1 indicates a perfect negative relationship, and 0 suggests no relationship. The formula for calculating the correlation coefficient involves dividing the covariance of the two variables by the product of their standard deviations, providing a standardized measure of the relationship between the variables.
What is the purpose of probability in statistics?
The purpose of probability in statistics is to quantify the likelihood or chance of a particular event occurring. It enables statisticians to make predictions, draw inferences from data, and assess the uncertainty associated with various outcomes. Probability theory forms the foundation of statistical methods and helps in decision-making, risk assessment, and various other applications in research, business, and everyday life.
How is the normal distribution used in statistical analysis?
The normal distribution is used in statistical analysis to describe and analyze data that follows a bell curve shape, with the majority of values clustered around the mean and decreasing as you move away from the mean in both directions. It is utilized to make probability judgments, calculate z-scores for hypothesis testing, estimate confidence intervals, and analyze the variability within a dataset. The properties of the normal distribution, such as the 68-95-99.7 rule and the Empirical Rule, help in making informed decisions and drawing conclusions in various fields including business, science, economics, and social sciences.







Have something to share?
Who is Worksheeto?
At Worksheeto, we are committed to delivering an extensive and varied portfolio of superior quality worksheets, designed to address the educational demands of students, educators, and parents.







Comments